#Bash on Ubuntu on Windows
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows 10/11 when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on how to build and set up your own personal media server using Ubuntu as an operating system and Plex (or Jellyfin) to not only manage your media, but to also stream that media to your devices both at home and abroad anywhere in the world where you have an internet connection. Its intent is to show you how building a personal media server and stuffing it full of films, TV, and music that you acquired through indiscriminate and voracious media piracy various legal methods will free you to completely ditch paid streaming services. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+, Crave or any other streaming service that is not named Criterion Channel. Instead whenever you want to watch your favourite films and television shows, you’ll have your own personal service that only features things that you want to see, with files that you have control over. And for music fans out there, both Jellyfin and Plex support music streaming, meaning you can even ditch music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 (or FLAC) collections.
On the hardware front, I’m going to offer a few options catered towards different budgets and media library sizes. The cost of getting a media server up and running using this guide will cost you anywhere from $450 CAD/$325 USD at the low end to $1500 CAD/$1100 USD at the high end (it could go higher). My server was priced closer to the higher figure, but I went and got a lot more storage than most people need. If that seems like a little much, consider for a moment, do you have a roommate, a close friend, or a family member who would be willing to chip in a few bucks towards your little project provided they get access? Well that's how I funded my server. It might also be worth thinking about the cost over time, i.e. how much you spend yearly on subscriptions vs. a one time cost of setting up a server. Additionally there's just the joy of being able to scream "fuck you" at all those show cancelling, library deleting, hedge fund vampire CEOs who run the studios through denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you step-by-step through installing Ubuntu as your server's operating system, configuring your storage as a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection between your server and your Windows PC, and then a little about started with Plex/Jellyfin. Every terminal command you will need to input will be provided, and I even share a custom #bash script that will make used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, Slackware etc. et. al.) and are aching to tell me off for being basic and using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and had fun putting everything together, then I would encourage you to return in a year’s time, do your research and set up everything with Docker Containers.
Lastly, this is a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with various Linux distributions (mostly Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users, but others (e.g. setting up shares) you will have to look up for yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise. All you will need is a basic computer literacy (i.e. an understanding of what a filesystem and directory are, and a degree of comfort in the settings menu) and a willingness to learn a thing or two. While this guide may look overwhelming at first glance, it is only because I want to be as thorough as possible. I want you to understand exactly what it is you're doing, I don't want you to just blindly follow steps. If you half-way know what you’re doing, you will be much better prepared if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it shouldn't take more than an afternoon or two to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, depending on the distribution there's close to no bloat. There are recent distributions available at this very moment that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Moreover, running Plex or Jellyfin isn’t resource intensive in 90% of use cases. All this is to say, we don’t require an expensive or powerful computer. This means that there are several options available: 1) use an old computer you already have sitting around but aren't using 2) buy a used workstation from eBay, or what I believe to be the best option, 3) order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can happen for a number of reasons, such as the playback device's native resolution being lower than the file's internal resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware. This means we should be looking for a computer with an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This specialized hardware makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software. This takes up much more of a CPU’s processing power and requires much more energy. But not all Quick Sync cores are created equal and you need to keep this in mind if you've decided either to use an old computer or to shop for a used workstation on eBay
Any Intel processor from second generation Core (Sandy Bridge circa 2011) onward has Quick Sync cores. It's not until 6th gen (Skylake), however, that the cores support the H.265 HEVC codec. Intel’s 10th gen (Comet Lake) processors introduce support for 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors brought with them hardware AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to hardware transcode a H.265 encoded file, it will fall back to software transcoding if given a 10bit H.265 file. If you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go shopping shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 on a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CAD/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology. It was only introduced with the first generation Ryzen CPUs and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could forgo having to keep track of what generation of CPU is equipped with Quick Sync cores that feature support for which codecs, and just buy an N100 mini-PC. For around the same price or less of a used workstation you can pick up a mini-PC with an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync cores. These little processors offer astounding hardware transcoding capabilities for their size and power draw. Otherwise they perform equivalent to an i5-6500, which isn't a terrible CPU. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system and it does everything up to 6th generation consoles just fine. The N100 is also a remarkably efficient chip, it sips power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper on AliExpress. They range in price from $170 CAD/$125 USD for a no name N100 with 8GB RAM to $280 CAD/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM. 16GB RAM might result in a slightly snappier experience, especially with ZFS. A 256GB SSD is more than enough for what we need as a boot drive, but going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the type of power adapter it ships with. The mini-PC I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as barrel plug 30W/12V/2.5A power adapters are easy to find and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build. It is also the most expensive. Thankfully it’s also the most easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a more limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to buy a USB 3.0 8TB external HDD. Something like this one from Western Digital or this one from Seagate. One of these external drives will cost you in the area of $200 CAD/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up such as detailed below.
If a single external drive the path for you, move on to step three.
For people with larger media libraries (12TB+), who prefer media in 4k, or care who about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC or used workstatiom as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives into the case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with three to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives, if we configured our drives in a RAIDz1 array we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, we don't need anything with hardware RAID controls (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform perfectly fine. Don’t worry too much about USB speed bottlenecks. A mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but many people swear by them.
When shopping for harddrives, search for drives designed specifically for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7. They will also often make use of CMR (conventional magnetic recording) as opposed to SMR (shingled magnetic recording). This nets them a sizable read/write performance bump over typical desktop drives. Seagate Ironwolf and Toshiba NAS are both well regarded brands when it comes to NAS drives. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark quite often when there is nothing at all wrong with that drive. It will likely even be good for another six, seven, or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, an .ISO of Ubuntu, and a way to make that thumbdrive bootable media.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against the server release. The server release is strictly command line interface only, and having a GUI is very helpful for most people. Not many people are wholly comfortable doing everything through the command line, I'm certainly not one of them, and I grew up with DOS 6.0. 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC. BalenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or you old PC/used workstation) in front of you, hook it directly into your router with an ethernet cable, and then plug in the HDD enclosure, a monitor, a mouse and a keyboard. Now turn that sucker on and hit whatever key gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Now, it's time to check that the HDDs we have in the enclosure are healthy, running, and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down as we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing by two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, as it is capable of automatically checking for errors against a checksum. It's more forgiving in this way, and it's likely that you'll be able to detect when a drive is dying well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". This poil will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command will look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If as an example you bought five HDDs and decided you wanted more redundancy dedicating two drive to this purpose, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this is known as RAIDz2 and is able to survive two disk failures.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that a pool is ready to go immediately after creation. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go right out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but we won't be dealing with them extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
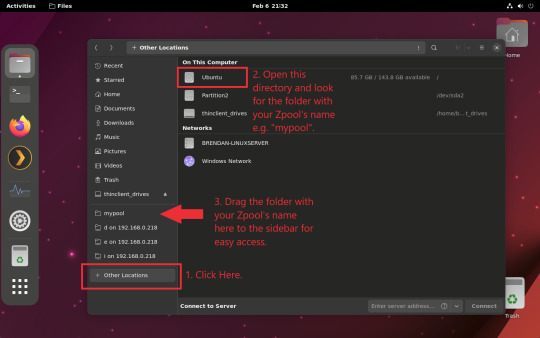
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your Ubuntu user password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable. Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Our next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read and write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash CUR_PATH=`pwd` ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]] then IS_ZFS=false else IS_ZFS=true fi if [[ $IS_ZFS = false ]] then df $CUR_PATH | tail -1 | awk '{print $2" "$4}' else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) > /dev/null TOTAL=$(($USED+$AVAIL)) > /dev/null echo $TOTAL $AVAIL fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = /home/"yourlinuxusername"/dfree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare “yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, everything will appear to work fine, and you will even be able to see and map the drive from Windows and even begin transferring files, but you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file next in the queue. And at the end it would reattempt to transfer whichever files failed the first time around. 99% of the time they’ll go through that second try, but this is still all a major pain in the ass. Especially if you’ve got a lot of data to transfer or you want to step away from the computer for a while.
It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will result in a black screen!
Now get back on your Windows PC, open search and look for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window. In the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and prompt asking for your username and password. Enter your Ubuntu username and password here.
If everything went right, you’ll be logged into your Linux computer. If the performance is sluggish, adjust the display options. Lowering the resolution and colour depth do a lot to make the interface feel snappier.
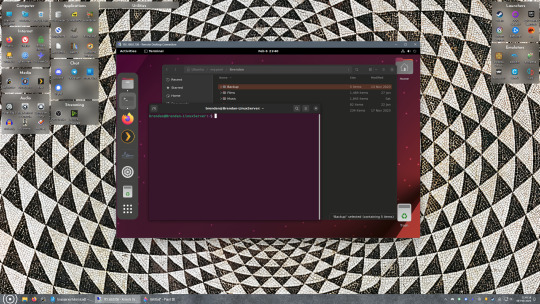
Remote access is how we're going to be using our Linux system from now, barring edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub to checking zpool status and updating software can all be done remotely.

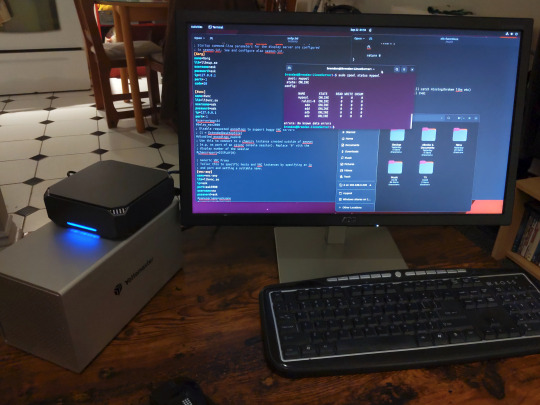
This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in a corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running. We’ve got Ubuntu up and running, our storage array is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex. It just works 99% of the time. That said, Jellyfin has a lot to recommend it by too, even if it is rougher around the edges. Some people run both simultaneously, it’s not that big of an extra strain. I do recommend doing a little bit of your own research into the features each platform offers, but as a quick run down, consider some of the following points:
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things: for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly or yearly subscription basis) in order to access to certain features, like hardware transcoding (and we want hardware transcoding) or automated intro/credits detection and skipping, Jellyfin offers some of these features for free through plugins. Plex supports a lot more devices than Jellyfin and updates more frequently. That said, Jellyfin's Android and iOS apps are completely free, while the Plex Android and iOS apps must be activated for a one time cost of $6 CDN/$5 USD. But that $6 fee gets you a mobile app that is much more functional and features a unified UI across platforms, the Plex mobile apps are simply a more polished experience. The Jellyfin apps are a bit of a mess and the iOS and Android versions are very different from each other.
Jellyfin’s actual media player is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files unless you've got it set up a certain way. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I had a pretty easy time getting my boomer parents and tech illiterate brother introduced to and using Plex and I don't know if I would've had as easy a time doing that with Jellyfin. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV in the office and the Android TV app for our smart TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
1K notes
·
View notes
Text
in wake of yet another wave of people being turned off by windows, here's a guide on how to dual boot windows and 🐧 linux 🐧 (useful for when you're not sure if you wanna make the switch and just wanna experiment with the OS for a bit!)
if you look up followup guides online you're gonna see that people are telling you to use ubuntu but i am gonna show you how to do this using kubuntu instead because fuck GNOME. all my homies hate GNOME.

i'm just kidding, use whatever distro you like. my favorite's kubuntu (for a beginner home environment). read up on the others if you're curious. and don't let some rando on reddit tell you that you need pop! OS for gaming. gaming on linux is possible without it.
why kubuntu?
- it's very user friendly
- it comes with applications people might already be familiar with (VLC player and firefox for example)
- libreoffice already preinstalled
- no GNOME (sorry GNOME enthusiasts, let me old man yell at the clouds) (also i'm playing this up for the laughs. wholesome kde/gnome meme at the bottom of this post.)
for people who are interested in this beyond my tl;dr: read this
(if you're a linux user, don't expect any tech wizardry here. i know there's a billion other and arguably better ways to do x y and/or z. what i'm trying to do here is to keep these instructions previous windows user friendly. point and click. no CLI bro, it'll scare the less tech savvy hoes. no vim supremacy talk (although hell yeah vim supremacy). if they like the OS they'll figure out bash all by themselves in no time.)
first of all, there'll be a GUI. you don't need to type lines of code to get this all running. we're not going for the ✨hackerman aesthetics✨ today. grab a mouse and a keyboard and you're good to go.
what you need is a computer/laptop/etc with enough disk space to install both windows and linux on it. i'm recommending to reserve at least a 100gb for the both of them. in the process of this you'll learn how to re-allocate disk space either way and you'll learn how to give and take some, we'll do a bit of disk partitioning to fit them both on a single disk.
and that's enough babbling for now, let's get to the actual tutorial:
🚨IMPORTANT. DO NOT ATTEMPT THIS ON A 32BIT SYSTEM. ONLY DO THIS IF YOU'RE WORKING WITH A 64BIT SYSTEM. 🚨 (win10 and win11: settings -> system -> about -> device specifications -> system type ) it should say 64bit operating system, x64-based processor.
step 1: install windows on your computer FIRST. my favorite way of doing this is by creating an installation media with rufus. you can either grab and prepare two usb sticks for each OS, or you can prepare them one after the other. (pro tip: get two usb sticks, that way you can label them and store them away in case you need to reinstall windows/linux or want to install it somewhere else)
in order to do this, you need to download three things:
rufus
win10 (listen. i know switching to win11 is difficult. not much of a fan of it either. but support's gonna end for good. you will run into hiccups. it'll be frustrating for everyone involved. hate to say it, but in this case i'd opt for installing its dreadful successor over there ->) or win11
kubuntu (the download at the top is always the latest, most up-to-date one)
when grabbing your windows installation of choice pick this option here, not the media creation tool option at the top of the page:

side note: there's also very legit key sellers out there who can hook you up with cheap keys. you're allowed to do that if you use those keys privately. don't do this in an enterprise environment though. and don't waste money on it if your ultimate goal is to switch to linux entirely at one point.
from here it's very easy sailing. plug your usb drive into your computer and fire up rufus (just double click it).

🚨two very important things though!!!!!!:🚨
triple check your usb device. whatever one you selected will get wiped entirely in order to make space for your installation media. if you want to be on the safe side only plug in the ONE usb stick you want to use. and back up any music, pictures or whatever else you had on there before or it'll be gone forever.
you can only install ONE OS on ONE usb drive. so you need to do this twice, once with your kubuntu iso and once with your windows iso, on a different drive each.
done. now you can dispense windows and linux left and right, whenever and wherever you feel like it. you could, for example, start with your designated dual boot device. installing windows is now as simple as plugging the usb device into your computer and booting it up. from there, click your way through the installation process and come back to this tutorial when you're ready.
step 2: preparing the disks for a dual boot setup
on your fresh install, find your disk partitions. in your search bar enter either "diskmgr" and hit enter or just type "partitions". the former opens your disk manager right away, the latter serves you up with this "create and format hard disk partitions" search result and that's what you're gonna be clicking.

you'll end up on a screen that looks more or less like in the screenshot below. depending on how many disks you've installed this might look different, but the basic gist is the same. we're going to snip a little bit off Disk 0 and make space for kubuntu on it. my screenshot isn't the best example because i'm using the whole disk and in order to practice what i preach i'd have to go against my own advice. that piece of advice is: if this screen intimidates you and you're not sure what you're doing here, hands off your (C:) drive, EFI system, and recovery partition. however, if you're feeling particularly fearless, go check out the amount of "free space" to the right. is there more than 30gb left available? if so, you're free to right click your (C:) drive and click "shrink volume"

this screen will pop up:

the minimum disk space required for kubuntu is 25gb. the recommended one is 50gb. for an installation like this, about 30gb are enough. in order to do that, simply change the value at
Enter the amount of space to shrink in MB: to 30000
and hit Shrink.
once that's done your partitions will have changed and unallocated space at about the size of 30gb should be visible under Disk 0 at the bottom like in the bottom left of this screenshot (courtesy of microsoft.com):

this is gonna be kubuntu's new home on your disk.
step 3: boot order, BIOS/UEFI changes
all you need to do now is plug the kubuntu-usb drive you prepared earlier with rufus into your computer again and reboot that bad boy.
the next step has no screenshots. we're heading into your UEFI/BIOS (by hitting a specific key (like ESC, F10, Enter) while your computer boots up) and that'll look different for everyone reading this. if this section has you completely lost, google how to do these steps for your machine.
a good search term would be: "[YOUR DEVICE (i.e Lenovo, your mainboard's name, etc.)] change boot order"
what you need to do is to tell your computer to boot your USB before it tries to boot up windows. otherwise you won't be able to install kubuntu.
this can be done by entering your BIOS/UEFI and navigating to a point called something along the lines of "boot". from "boot order" to "booting devices" to "startup configuration", it could be called anything.
what'll be a common point though is that it'll list all your bootable devices. the topmost one is usually the one that boots up first, so if your usb is anywhere below that, make sure to drag and drop or otherwise move it to the top.
when you're done navigate to Save & Exit. your computer will then boot up kubuntu's install wizard. you'll be greeted with this:

shocker, i know, but click "Install Kubuntu" on the right.
step 4: kubuntu installation
this is a guided installation. just like when you're installing windows you'll be prompted when you need to make changes. if i remember correctly it's going to ask you for your preferred keyboard layout, a network connection, additional software you might want to install, and all of that is up to you.
but once you reach the point where it asks you where you want to install kubuntu we'll have to make a couple of important choices.

🚨 another important note 🚨
do NOT pick any of the top three options. they will overwrite your already existing windows installation.
click manual instead. we're going to point it to our unallocated disk space. hit continue. you will be shown another disk partition screen.
what you're looking for are your 30gb of free space. just like with the USB drive when we were working with rufus, make sure you're picking the right one. triple check at the very least. the chosen disk will get wiped.

click it until the screen "create a new partition" pops up.
change the following settings to:
New partition size in megabytes: 512
Use as: EFI System Partition
hit OK.
click your free space again. same procedure.
change the following settings to:
New partition size in megabytes: 8000 (*this might be different in your case, read on.)
Use As: Swap Area
hit OK
click your free space a third time. we need one more partition.
change the following settings to:
don't change anything about the partition size this time. we're letting it use up the rest of the resources.
Use as: Ext4 journaling system
Mount Point: /
you're done here as well.
*about the 8000 megabytes in the second step: this is about your RAM size. if you have 4gb instead type 4000, and so on.
once you're sure your configuration is good and ready to go, hit "Install Now". up until here you can go back and make changes to your settings. once you've clicked the button, there's no going back.
finally, select your timezone and create a user account. then hit continue. the installation should finish up... and you'll be good to go.
you'll be told to remove the USB drive from your computer and reboot your machine.
now when your computer boots up, you should end up on a black screen with a little bit of text in the top left corner. ubuntu and windows boot manager should be mentioned there. naturally, when you click ubuntu you will boot into your kubuntu. likewise if you hit windows boot manager your windows login screen will come up.
and that's that folks. go ham on messing around with your linux distro. customize it to your liking. make yourself familiar with the shell (on kubuntu, when you're on your desktop, hit CTRL+ALT+T).
for starters, you could feed it the first commands i always punch into fresh Linux installs:
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install vim
(you'll thank me for the vim one later)
turn your back on windows. taste freedom. nothing sexier than open source, baby.
sources (mainly for the pictures): 1, 2
further reading for the curious: 1, 2
linux basics (includes CLI commands)
kubuntu documentation (this is your new best friend. it'll tell you everything about kubuntu that you need to know.
and finally the promised kde/gnome meme:

#windows#linuxposting#had a long day at work and i had to type this twice and i'm struggling to keep my eyes open#not guaranteeing that i didn't skip a step or something in there#so if someone linux savvy spots them feel free to point them out so i can make fixes to this post accordingly#opensource posting
122 notes
·
View notes
Text
Audacity for Debian-based Linux
So, some time around 2020/2021, Audacity for Linux from the repositories of Debian-based distros (including Ubuntu, Mint, etc.) no longer had access to high quality stretch (change tempo, change pitch, shifting slider). This appears to be due to a combination of Debian no longer updating Audacity at all past 2.4.2 (as Audacity's new owners from 3.0.0 on have had...issues, to put it lightly), but also the fact that 2.4.2 specifically was requiring a version of the SBSMS library past what Debian had. It's still the case that the apt version of Audacity on Linux Mint still lacks the high quality stretch functions.
The workaround for this is to compile from source. HOWEVER. Be apprised that if you specifically go for version 2.4.2, there is still a bug around SBSMS, which causes Audacity to crash when attempting high quality stretching. Apparently, if you go for versions afterwards (3.0+, new Audacity owners), or the version before (2.3.3), you will not run into this issue.
I am stubborn, so I have verified that I can now open Audacity 2.4.2 and do a high quality pitch change without crashing. Here are the solution options. Know that both are still compiling from source.
Option 1: Do it manually command by command on the terminal
You will, however, notice that the important download link for the patch is broken. You must get it from here.
Note that you should preface all of the commands listed in that post with "sudo", or they will likely throw an error. (Or do whatever you need to for terminal to continuously recognize root access.) In addition, note that the "pre-installation test" section is not optional. Audacity will not run if the "Portable Settings" folder is not created, and furthermore, the "Portable Settings" folder and all containing files need to have write permissions enabled to the relevant non-root group/owner.
Whether you installed manually or used the script, you will need to go to "/usr/local/share/audacity/audacity-minsrc-2.4.2/build/bin/Release" to launch Audacity. In the file explorer window, you can click the button to the left of the magnifying glass to switch to text input where you can copy and paste the above path. Or, from /home, go up one level, and then navigate through manually.
Change the launcher's icon and add it to the start menu/desktop, per your specific distro and desktop environment.
Option 2: Modify and run a bash script
I found a helpful Youtube video stepping through the process, before they link to a bash script automating the whole thing. However, the script does not include the 2.4.2 patch. There are also a few modifications that need to be done to the script.
Modifications to make (right click the .sh file, open with, pick some text editor):
Line 35: change the dl_directory to match your own system. (Specifically, you probably need to replace "piuser" with your own account name.)
This change also needs be done on lines 115, 116, and 120 (or replace the hard coded parts with "${DL_DIRECTORY}").
Line 77 (optional): add "patch" as a dependent package to check. Like Python, it's mostly likely already installed, so you could leave this commented out.
Lines 139-142: Not a modification, but a note that I didn't end up using this (left it commented out), so I did have to download the 2.4.2 source code from fosshub manually and put it in the location specified by dl_directory. I also put the patch there. If you do want to try to automate the download, you'll not only have to add another line to also download the patch file, but both the source code for 2.4.2 and the patch have hyphens in their urls, so you need to either add backslashes to escape them, or enclose the entire url in quotation marks. But I also can't guarantee that either of those things will work, since I ended up doing the downloads manually.
Line 150: Per the manual installation above, the patch needs to be applied before the build. Add this code block at line 150 (after the script checks to see if the "Build" folder exists):
#SBSMS patch required for 2.4.2 if [ -f "${DL_DIRECTORY}/changepitch.patch" ]; then sudo cp "${DL_DIRECTORY}/changepitch.patch" "${DIRECTORY}/${VERSION}" fi sudo patch -p 1 < changepitch.patch
That's it for changing the script. Save it, close out of the text editor. (If you decided not to try letting the script do the downloads, then make sure you download the source code and the patch and put them in the dl_directory location at this point.)
Enable the script to be executable. (Right click the .sh file, Properties. On the Permissions tab, check that "Allow executing file as a program" is checked.)
Double click the .sh file. I suggest doing the "Run In Terminal" option so you can see the progress. (And if it's really short, probably something went wrong. The build section takes 20 minutes.)
This script does not include installing the offline manual for Audacity. That is covered in the guide posted in Option 1. Sorry, you'll have to do some terminal typing after all.
Whether you installed manually or used the script, you will need to go to "/usr/local/share/audacity/audacity-minsrc-2.4.2/build/bin/Release" to launch Audacity. In the file explorer window, you can click the button to the left of the magnifying glass to switch to text input where you can copy and paste the above path. Or, from /home, go up one level, and then navigate through manually.
Change the launcher's icon and add it to the start menu/desktop, per your specific distro and desktop environment.
#linux#linux mint#ubuntu#debian#audacity#category: other#vibrating at the mashups now once again at my fingertips
9 notes
·
View notes
Text
I think it's a really good sign of growth and healing that I'm finding myself increasingly repulsed by the kind of portability extremism that once compelled me.
One of the biggest and worst examples was shell scripts. /bin/sh was the Bourne shell in UNIXv7 (prior to that, there was the Thompson shell, and thankfully I managed to keep my mind cancer from metastasizing further backwards in time to try to achieve compatibility with that shell too). After the Bourne shell, every /bin/sh on every system was a Bourne-like shell, and if you thought that meant you could just write something that worked, take a glance at:
GNU Autoconf's Portable Shell documentation.
Sven Mascheck's various pages.
Paul Jarc's "lintsh" notes.
Ubuntu's "dash"-as-/bin/sh guide.
and others which you can find from there.
Now, a healthy person simply rejects this problem space. But for years, I was obsessed with writing shell scripts which would work on all /bin/sh still in production. It started as a growing annoyance with so many programs depending on bash - I was otherwise happily using a system with a more minimal shell at the time, and the limitations of my beloved Nokia N900 as a pocket Linux device gave me some real reason to prefer "reducing bloat" back then. Of course if it mattered to me, my compassion generalized it to everyone else in the same boat (everyone real or imagined... and in this case, mostly imagined). Then one day in the first year of my career as a software developer I got into a small argument with a coworker about them mandating #!/bin/bash instead of #!/bin/sh in our shell scripts - after he asserted that it was unreasonable to expect developers to remember what is or isn't a bashism, my maladaptive narcissistic cope reflexively kicked into full gear and now I had something to prove.
I still remember bits of that evening after work. It's... kinda horrifying looking back on it, because I was aware of what was happening in my mind. I was aware that I was basically starting to involuntarily, compulsively terraform my own preferences and values about shell scripts, from the modest and real and practical "I just want scripts to run on my N900s (BusyBox ash implementation for /bin/sh), and maybe also my Debian boxes (dash for /bin/sh)" to some perverse "principled" stance with poorly-defined scope which was divorced from any specific concrete goals. I had seen this runaway snowballing of artificial nitpicky values happen in my mind before, and I recognized that what I was doing in my head was feeding it, that it was happening again or that I was making it happen again, and I felt some conflict with that, I could see how it was bad... but back then I didn't know how to do anything about it. I didn't know how to diffuse those wants back then. I could in some technical sense, have chosen to not do it, but I couldn't stop wanting to, and I couldn't stop rationalizing it.
So I became the kind of guy that basically had every caveat mentioned on the above pages memorized. I even went as far as having a Solaris 10 VM, some old Android phones, and a PDP emulator running UNIXv7, so that I could test things not mentioned or not elaborated on those pages. But since it's really costly to remember so much trivia, I only remembered the caveats themselves, not necessarily which shells/systems they applied to. I could tell you off the top of my head "well you see, on some shells, 'set -e' will not affect the code inside functions", but I couldn't tell you which shells - I just had the caveats grouped by
"only matters on systems that no one runs anymore",
"only matters in situations you/we will never need to be compatible with (like Solaris 10's /bin/sh)",
"only matters if you want portability on Windows ports of UNIX-y shell stuff",
"only matters if you want portability beyond just Linux", and
"only matters if you want portability beyond just 'bash'".
I also used to have a little template for shell portability disclaimers that I would add to my shell scripts, deleting/re-adding lines as-needed:
# This script is compatible with Bourne and POSIX shells. # EXCEPT for the following exceptions (last verified on YYYY-MM-DD): # Comments (Appeared in 1981, still not universal around 1987) # Functions (First appeared in SVR2 Bourne shells in 1984) # `mkfifo` (First appeared sometime circa 1984, possibly earlier; unsure) # `test -p` (First appeared in SVR1 Bourne shell in 1983). # `wait` exit status (Missing in Almquist shell until 4.4BSD in 1993) # `hash` builtin (First appeared in SVR2 Bourne shells in 1984) # `type` builtin (First appeared in SVR2 Bourne shells in 1984) # $() is used instead of `` (not supported by some ancient Bourne shells) # `shift` when no positional parameters (broke some old MIPS RISC/os shells) # ${VAR%glob} substitution (Solaris (<= 10) /bin/sh does not support it) ...
That version of me looked at my old esceval.sh with pride, as if it was important or worthwhile. It tries to use modern-ish POSIX shell features but falls back to portable shell if it must. Basically every single line has at least one detail that is a deliberate portability choice. Almost every degree of freedom has been optimized for portability (and then some performance optimization within that) - change almost anything and it's probably less portable.
I revisited "esceval" for the first time in years this past week, and I noticed something really nice. I no longer have enough appetite for this portabiliy stuff. I'm too acutely aware, down to my motivating emotions, that it's a waste of my life. I'm once again in touch with actual concrete use-cases and benefits that have high odds of coming up in my life. I've re-learned to value myself and my goals more than this portability shit.
So I'm going to delete the portability fallback from "esceval.sh". I'm done trying to figure out what the portability fallback looks like for the other esceval pieces that I still want to finish. Unless I'm being compensated better than I can get elsewhere, I'm never again going to lift a finger to support Solaris 10 /bin/sh, or Android phones lobotomized to the point of not having a "printf" command in their shell, or anything else that isn't at least POSIX-compatible shell. And even then I'd suggest implementing that by writing a backpiler from modern shell to older. Maybe I'll answer portability questions if I still remember the answer and can say it off the top of my head - I enjoy helping people after all.
And it goes deeper than that. I'm very done giving Bourne-style shells nearly as much time and effort as I've given them so far. They're good DSLs for redirecting file descriptors and sorta okay DSLs for invoking and managing processes, and that's about it. As an unfortunate practical matter, Bourne-style shell is one of the most widely deployed programming language families, so if the goal is "I want to be able to give this tiny CLI to a coworker so they can run it on their machine with minimal human hassle", it can be nice to have a #!/bin/sh implementation (but so is having a couple statically compiled executables for the common platforms and a cross-compiler ready for the rest, or a Python script, or [...]).
It'll take me some time to figure out exactly where that balance is, and to fully unlearn the various hangups and compulsions that I've built up which motivate writing a /bin/sh script instead of something else, but what I've been doing so far definitely ain't that balance, ain't even close, and now I finally have a strong-enough hunger for breaking free and moving in the direction of that healthier balance.
#software#how i waste my abilities#how i used to waste my abilities#bourne shell#mentalisttraceur personal
13 notes
·
View notes
Note
Being bashed with a computer running any operating system will hurt but often in different ways:
Mint; feels like getting iced
Windows; turns out broken glass tastes a lot like blood
Mac; fruit can be surprisingly painful
Kali; bruses aren't the worst result of a dragon attack
Android; Arnold may be old, but he still hits hard
Ubuntu; orange flavour is really just acid in the wound
mint hurts because why
There are four main types of painful food:
Menthol (Mint): Feels cold
Capsaicin (Pepper): Feels hot
Carbonation: Feels fizzly
Alcohol: Feels like stinging
These foods all existed in balance, until the carbonation attacked.
3K notes
·
View notes
Text
Wetterdaten visualisieren mit XSLT & Apache FOP – Teil 1: PNG-Erzeugung am PC

Für ein größeres Vorhaben musste ich mich wieder etwas in XSLT & Apache FOP einarbeiten. Statt nur mit Beispiel-XMLs zu testen, habe ich mir ein kleines, aber sinnvolles Projekt gesucht – und so entstand die Idee, eine Wetterstation mit ePaper-Anzeige zu bauen. https://youtu.be/DMgWOIySd4I Im aktuellen Stadium wird das Bild lokal auf meinem Rechner erzeugt und anschließend auf meinen externen Webserver (all-inkl.com) hochgeladen.Später soll das Ganze komplett lokal auf einem Raspberry Pi laufen – dazu mehr im zweiten Teil der Serie. Automatisierung per Bash-Skript Der komplette Prozess – vom Abrufen der Wetterdaten über die Transformation mit XSLT bis hin zur PNG-Erzeugung – läuft automatisiert in einem einzigen Bash-Skript ab.Dieses Skript lässt sich später problemlos auf einem Raspberry Pi ausführen, sodass das System komplett autark arbeitet. Aktuell lade ich das generierte Bild auf meinen Webserver bei All-inkl., von dem sich der ESP32 das PNG regelmäßig abholt. Doch: Wenn Raspberry Pi und ESP32 im selben lokalen Netzwerk sind, kann sogar der externe Webserver entfallen.In diesem Fall reicht ein kleiner Webserver auf dem Pi, etwa via lighttpd oder python3 -m http.server, um das Bild bereitzustellen. Benötigte Komponenten & Tools Damit du das Projekt 1:1 nachbauen kannst, benötigst du folgende Tools und Hardware: Software & Umgebung - Leistungsstarke Entwicklungsumgebungz. B. IntelliJ IDEA oder eine andere IDE mit XML/XSLT-Unterstützung - WSL mit Ubuntu (unter Windows)Wird benötigt für Tools wie curl, Bash-Skripte und einfache Paketinstallation(alternativ geht auch ein nativer Linux-Rechner oder Raspberry Pi) - Apache FOPZur Umwandlung der XSL-FO-Datei in ein PNGDownload Apache FOP - Geo-Koordinaten deines Standorts (zwingend erforderlich für API-Abfragen) - Ohne diese gibt die Meteomatics API keine Wetterdaten zurück. - Du kannst deine Latitude / Longitude ganz einfach über Google Maps ermitteln: - Google Maps öffnen → Rechtsklick auf Standort → klick auf die angezeigten Koordinaten - die Koordinaten wie 52.1385884, 10.9670108 liegen nun in der Zwischenablage Hardware - ePaper Display (z. B. 6" Inkplate)Unterstützt PNG-Anzeige und kann später als stromsparendes Dashboard verwendet werden→ kompatibel mit ESP32 & USB-C-Anschluss - USB-C DatenkabelZur Verbindung mit dem PC/Mac beim späteren Flashen des Controllers Inkplate 6 Zoll und 6-Farb-Display Das in diesem Projekt verwendete Inkplate 6 Zoll ePaper Display habe ich bereits auf meinem Blog vorgestellt. Daher gehe ich auf dieses nicht speziell ein. - Erfahrungsbericht: Wie gut sind die neuen E-Paper Displays von Soldered? - API-Daten des Bitaxe Gamma mit ESP32 und E-Paper-Display visualisieren Projektdateien Das komplette Projekt mit Beispieldaten, XSLT-Template und Bash-Skript findest du auf GitHub: github.com/StefanDraeger/xml2weatherpng Warum das Inkplate 6" ePaper Display die perfekte Wahl ist Für dieses Projekt setze ich das Inkplate 6" ein – ein vielseitiges ePaper-Display mit integriertem ESP32-Mikrocontroller. Dieses Board bringt alles mit, was man für eine smarte, energieeffiziente Wetteranzeige benötigt: - ePaper-Technologie: Einmal dargestellte Inhalte bleiben auch ohne Stromzufuhr sichtbar. Dadurch eignet sich das Display ideal für statische Inhalte wie Wetterdaten, die nur in Intervallen aktualisiert werden müssen. - Integrierter ESP32: Der verbaute Mikrocontroller ermöglicht die direkte WLAN-Anbindung und den Abruf des Wetterbildes – ohne zusätzliches Steuergerät. - LiPo-Batterieanschluss: Dank der Unterstützung für LiPo-Akkus kann das Gerät völlig autark und kabellos betrieben werden. - Deep Sleep-Modus: Nach dem Herunterladen und Anzeigen des Wetterbildes wechselt der ESP32 in den energieeffizienten Schlafmodus, um Strom zu sparen. Der Bildschirminhalt bleibt dabei vollständig erhalten. Inkplate 6Inch ePaperDisplay - aktuelle Wetterdaten Inkplate 6Inch ePaperDisplay - Ansicht von der Seite Inkplate 6Inch ePaperDisplay - Sicht aus jedem Winkel möglich Inkplate 6Inch ePaperDisplay - Taste WakeUp Inkplate 6Inch ePaperDisplay - USB-C-Schnittstelle und RESET Taster Inkplate 6Inch ePaperDisplay - LiPo Batterie Diese Kombination aus sparsamer Anzeige, kabellosem Betrieb und einfacher WLAN-Anbindung macht das Inkplate 6" zur idealen Hardwarebasis für dieses Projekt – besonders für den Einsatz im Wohnbereich, Garten oder an Orten ohne ständige Stromversorgung. Wetterdaten via Meteomatics API beziehen Im ersten Schritt legen wir uns einen kostenlosen Account bei meteomatics.com an. Damit erhalten wir Zugriff auf die Wetterdaten-API, die wir später im Projekt verwenden. Parameter des kostenfreien Accounts von Meteomatics Kostenloses Kontingent: Mit dem Basic-Account sind bis zu 500 API-Abfragen pro Tag möglich – mehr als ausreichend, um die Wetterdaten im 15-Minuten-Intervall abzurufen: 24 h * 60 min / 15 min = 96 Abfragen pro Tag Der Login zum kostenlosen Account ist auf der Webseite etwas versteckt. Hier der direkte Link:Kostenloses Meteomatics-Konto erstellen Nach der Registrierung erhältst du Benutzername und Passwort, mit denen du später ganz einfach via curl oder in deinem Bash-Skript auf die Wetterdaten zugreifen kannst. Die Meteomatics API im Überblick Die Meteomatics Weather API ist sehr flexibel aufgebaut und liefert Wetterdaten in verschiedenen Formaten (XML, CSV, JSON, PNG etc.).In diesem Projekt nutzen wir die XML-Ausgabe, da sie sich perfekt mit XSLT weiterverarbeiten lässt. Dokumentation & Einstieg Die offizielle API-Dokumentation findest du hier: Getting Started mit der Meteomatics API Dort findest du: - Authentifizierungsbeispiele (curl, Python, etc.) - Parameterübersicht (Temperatur, Luftfeuchtigkeit, Wetterlage, u. v. m.) - Ausgabeformate (XML, JSON, PNG, CSV) - Struktur der URL-Abfragen Nachfolgend zeige ich dir Schritt-für-Schritt wie du diese Daten via curl im XML Format lädst. Beispiel-Abfrage (XML) Sobald du deinen Account und deine Koordinaten hast, kannst du z. B. folgende Wetterwerte abfragen: - Temperatur in 2 m Höhe (t_2m:C) - Relative Luftfeuchtigkeit (relative_humidity_2m:p) - Wettersymbol-ID (weather_symbol_1h:idx) curl -u "username:passwort" "https://api.meteomatics.com/now/t_2m:C,relative_humidity_2m:p,weather_symbol_1h:idx/52.1385884,10.9670108/xml" > wetter.xml Diese Abfrage liefert die aktuellen Wetterdaten als strukturiertes XML in der Daten wetter.xml, das wir im nächsten Schritt weiterverarbeiten werden. BENUTZER 2025-06-12T07:05:15Z OK 14.1 77.9 1 💡 Ich führe alle curl-Befehle unter einem lokalen Linux-System via WSL (Windows Subsystem for Linux) auf meiner Windows 11 Maschine aus.WSL lässt sich mit wenigen Klicks installieren – eine Anleitung findest du auf meinem YouTube Kanal im Video Linux unter Windows 11 - So geht’s Alternativ kann das Projekt natürlich auch direkt auf einem nativen Linux-System oder einem Raspberry Pi ausgeführt werden. Was ist XSLT – und wie verarbeitet man damit XML? XSLT (Extensible Stylesheet Language Transformations) ist eine Sprache, mit der man XML-Daten in andere Formate überführen kann – z. B. HTML, Text oder wie in unserem Fall XSL-FO, das wir später in ein PNG-Bild umwandeln. Während man in vielen Tutorials häufig das Durchlaufen mit for-each sieht, verwende ich in diesem Projekt eine gezielte, direkte Abfrage einzelner XML-Knoten.So bleibt das Layout klar strukturiert und wir behalten die Kontrolle über jede Ausgabezeile. Grundstruktur einer XSLT-Datei Zugriff auf einzelne Werte aus wetter.xml Statt Schleifen nutze ich in den einzelnen -Elementen direkte XPath-Abfragen wie diese: Temperatur: °C Genauso lässt sich auch der Zeitstempel (z. B. dateGenerated) gezielt ansprechen: Vorteil dieser Methode - Einfaches, lesbares Layout (insbesondere bei fixen Daten wie Temperatur, Luftfeuchte, Wettersymbol) - Kein unnötiges Durchlaufen von Elementen - Exakte Kontrolle über die Formatierung jedes einzelnen Wertes Wetter-Icons für die aktuelle Lage Um die aktuelle Wetterlage visuell darzustellen, verwende ich Wetter-Symbole im PNG-Format. Icons herunterladen Die passenden Icons können direkt bei Meteomatics kostenfrei heruntergeladen werden:mm_api_symbols.tar.gz – Meteomatics Widget Icons Bereits vorbereitet im GitHub-Repository Im Original-Archiv stimmen die Dateinamen leider nicht direkt mit den weather_symbol_1h:idx-IDs der API überein.Damit das Einbinden in XSLT funktioniert, müssten die Dateien eigentlich manuell umbenannt werden – aber das habe ich bereits für dich erledigt. Du findest im GitHub-Repository einen fertigen Ordner mit allen Symbolen, korrekt benannt nach der ID: images/104.png, images/1.png, usw. Du musst also nichts mehr selbst umbenennen. Zugriff im XSLT Mit den umbenannten Dateien funktioniert der Zugriff auf das passende Icon ganz einfach per external-graphic: Die PNG-Dateien liegen im Ordner images/ relativ zur Ausgabe. Das XSLT-Template für unser Wetterlayout Nachdem wir nun die Wetterdaten im XML-Format lokal gespeichert haben, erstellen wir im nächsten Schritt das passende XSLT-Template, das diese Daten in ein visuelles Layout überführt. Ziel ist es, ein XSL-FO-Dokument zu erzeugen, das von Apache FOP in ein PNG-Bild umgewandelt werden kann. Dieses Bild zeigt: - den aktuellen Standortnamen (hier: Schöningen), - das Datum und die Uhrzeit der Abfrage, - die Temperatur in °C, - die Luftfeuchtigkeit in Prozent, - sowie ein passendes Wettersymbol auf Basis der weather_symbol_1h:idx-ID. Das Layout orientiert sich an einem kompakten Infodisplay, optimiert für die Darstellung auf einem ePaper-Display mit 4,2 oder 5 Zoll. Die einzelnen Werte werden direkt aus dem XML-Dokument ausgelesen – ohne Schleifen – und gezielt in fo:block-Elemente geschrieben. Das sorgt für ein sauberes, stabiles und gut kontrollierbares Layout. Im folgenden Abschnitt siehst du den vollständigen Aufbau des Templates, das du bei Bedarf jederzeit an dein eigenes Design oder zusätzliche Wetterparameter anpassen kannst. XSL Dokument als Template Schöningen TEMPERATUR °C LUFTFEUCHTIGKEIT % Bildgenerierung mit Apache FOP auf der Kommandozeile Sobald wir unser XML mit den Wetterdaten und das passende XSLT-Template vorbereitet haben, nutzen wir Apache FOP, um daraus ein fertiges PNG-Bild zu erzeugen. Apache FOP ist ein Kommandozeilen-Tool, das XSL-FO-Dateien (Formatting Objects) in verschiedene Formate wie PDF, PNG oder SVG umwandeln kann. Voraussetzungen Stelle sicher, dass du: - Java installiert hast (java -version) - Apache FOP heruntergeladen und entpackt hast - dich im Verzeichnis der FOP-Binärdateien befindest oder fop im Pfad liegt Der Befehl fop -xml wetter.xml -xsl meteomatics2fo.xsl -png output/forecast.png 🔍 Erklärung der Parameter: - -xml wetter.xml: Die XML-Datei mit den aktuellen Wetterdaten - -xsl meteomatics2fo.xsl: Dein XSLT-Template, das die Daten in ein Layout überführt - -png forecast.png: Der Name der Ausgabedatei – in diesem Fall ein PNG-Bild erstellte Datei forecast.png durch Apache FOP Java unter WSL installieren Für die Ausführung von Apache FOP ist eine funktionierende Java-Umgebung erforderlich.Auch wenn Java bereits unter Windows installiert ist, musst du es innerhalb von WSL (z. B. Ubuntu) separat installieren, da beide Umgebungen unabhängig voneinander arbeiten. Installation unter Ubuntu/WSL: sudo apt update sudo apt install default-jre Alternativ kannst du auch das JDK installieren, falls du zusätzlich Java-Programme entwickeln willst: sudo apt install default-jdk Nach der Installation kannst du mit folgendem Befehl prüfen, ob Java korrekt eingerichtet ist: java -version Damit steht dem Einsatz von Apache FOP innerhalb deiner WSL-Umgebung nichts mehr im Weg. Automatischer Upload per SCP ohne Passwortabfrage Damit das generierte Wetterbild (forecast.png) regelmäßig und automatisch auf deinen Webserver hochgeladen werden kann (z. B. per CronJob), verwenden wir den SCP-Befehl – allerdings ohne Passwortabfrage. Da SCP standardmäßig keine Passwortübergabe erlaubt, müssen wir einmalig ein SSH-Schlüsselpaar erstellen und den öffentlichen Schlüssel auf den Server übertragen. SSH-Key erstellen Führe folgenden Befehl in deiner Linux-/WSL-Konsole aus: ssh-keygen -t rsa -b 4096 -C "[email protected]" - Der Kommentar (hier deine E-Mail-Adresse) ist optional. - Drücke einfach ENTER bei der Frage nach dem Speicherpfad (~/.ssh/id_rsa ist Standard). - Lege kein Passwort fest, damit die Verbindung automatisiert erfolgen kann. Öffentlichen Schlüssel auf den Webserver übertragen Jetzt lädst du deinen öffentlichen Schlüssel auf den Server (nur einmal nötig): ssh-copy-id benutzer@domain Gib bei der ersten Verbindung dein normales Passwort ein.Anschließend kannst du dich ohne Passwortabfrage per SSH/SCP verbinden. Bild hochladen per SCP Jetzt kannst du dein Bild mit einem einfachen Befehl hochladen: scp ./output/forecast.png benutzer@domain:/pfad/wetterdisplay/forecast.png Der Upload erfolgt in Sekunden – perfekt für die Einbindung in ein Bash-Skript oder Cronjob. Das Wetterbild auf dem Inkplate 6 anzeigen Nachdem wir im ersten Teil ein PNG mit aktuellen Wetterdaten generiert haben, geht es nun darum, dieses Bild auf einem ePaper-Display anzuzeigen.Ich verwende dafür das Inkplate 6 – ein stromsparendes, ESP32-basiertes ePaper-Board mit 6-Zoll-Anzeige und WLAN. Inkplate 6Inch ePaperDisplay - aktuelle Wetterdaten Inkplate 6Inch ePaperDisplay - Ansicht von der Seite Über eine einfache WLAN-Verbindung lädt das Board das Wetterbild in regelmäßigen Abständen herunter und stellt es direkt auf dem Display dar – ganz ohne HTML, Browser oder App.Im folgenden Code-Beispiel siehst du, wie das Bild mit wenigen Zeilen Code automatisch aktualisiert wird. Boardtreiber für die Inkplate Displays Damit wir das Board überhaupt programmieren können, müssen wir den Boardtreiber installieren, dazu kopieren wir die nachfolgende Adresse in Datei > Einstellungen > Zusätzliche Boardverwalter-URLs. https://raw.githubusercontent.com/SolderedElectronics/Dasduino-Board-Definitions-for-Arduino-IDE/master/package_Dasduino_Boards_index.json Nachdem der Index aktualisiert wurde, können wir die Schaltfläche "Boardverwalter" im linken Menü der Arduino IDE wählen und dort nach Inkplate suchen. In meinem Fall habe ich die aktuelle Version 8.1.0 installiert. Benötigte Bibliothek für das Inkplate Display Zusätzlich zum Boardtreiber benötigen wir noch den Treiber für das ePaperDisplay, diesen finden wir im Bibliothenverwalter wenn wir nach InkplateLibrary suchen. Bei der Installation der Bibliothek hatte ich zunächst Probleme weil die Sourcen nicht gefunden wurden. Die Lösung war zunächst das ich das GitHub Repository SolderedElectronics/Inkplate-Arduino-library als ZIP-Datei heruntergeladen habe und diese dann über Sketch > Bibliothek einbinden > ZIP-Bibliothek hinzufügen... installiert habe. Quellcode /* * Titel : Wetteranzeige mit dem Inkplate 6 ePaper-Display * Beschreibung : Dieses Programm lädt ein zuvor erzeugtes PNG-Bild mit aktuellen Wetterdaten * von einem Webserver herunter und zeigt es auf dem stromsparenden ePaper-Display an. * Das Bild wird in regelmäßigen Abständen neu geladen (alle 30 Minuten). * * Author : Stefan Draeger * Webseite : https://draeger-it.blog * Blogbeitrag : https://draeger-it.blog/wetterdaten-visualisieren-mit-xslt-apache-fop-teil-1-png-erzeugung-am-pc/ */ #include "HTTPClient.h" // Für HTTP-Anfragen (Bild abrufen) #include "WiFi.h" // Für WLAN-Verbindung #include "Inkplate.h" // Bibliothek für das Inkplate ePaper-Display // URL zum PNG-Bild mit den generierten Wetterdaten String forecastUrl = "http://ressourcen-draeger-it.de/wetterdisplay/forecast.png"; // HTTP- und WiFi-Clients vorbereiten (werden im drawImage intern genutzt) HTTPClient sender; WiFiClient wifiClient; // Display-Objekt erzeugen (automatische Modell-Erkennung, z. B. Inkplate 6") Inkplate display; // WLAN-Zugangsdaten const char* ssid = "abc"; // SSID deines WLANs const char* password = "123"; // WLAN-Passwort void setup() { Serial.begin(115200); // Serielle Ausgabe zur Debug-Überwachung // WLAN im Station-Modus aktivieren und verbinden WiFi.mode(WIFI_MODE_STA); WiFi.begin(ssid, password); while (WiFi.status() != WL_CONNECTED) { delay(500); Serial.print("."); // Warteanimation während der Verbindung } Serial.println(); Serial.print("Verbunden mit IP: "); Serial.println(WiFi.localIP()); // Display initialisieren (muss einmalig aufgerufen werden) display.begin(); } void loop() { // Display vollständig löschen display.clearDisplay(); display.display(); // Erstes Update zur Bestätigung des Clearings display.fillScreen(INKPLATE_WHITE); // Hintergrundfarbe setzen // Bild von der angegebenen URL laden und anzeigen // Parameter: URL, X-Position, Y-Position, Dithering aktiv, nicht invertieren display.drawImage(forecastUrl, 10, 0, true, false); display.display(); // Anzeige aktualisieren // 30 Minuten Pause (1800000 Millisekunden), danach wiederholen delay(1800000); } Read the full article
0 notes
Text
How to Install
Looking for easy, step-by-step guides on how to install everything from software to home devices? Our "How to Install" blog provides clear, beginner-friendly instructions to help you get things up and running without the hassle. Whether you're setting up a new app, assembling tech gadgets, or configuring tools, we simplify the process for you. Each post is written with accuracy and user convenience in mind.
How to Install How to Install Printers Without CD How to Install Webcam Drivers How to Install SSH How to Install Pixelmon How to Install OptiFine How to Install Fabric How to Install Zend Framework with XAMPP on Windows How to Install Roblox on Chromebook How to Install Roblox Studio How to Install Firefox on Mac How to Install Firefox on Linux How to Install Firefox on Windows How to Install Java Step-by-Step Guide for Beginners How to Install Java on Mac Follow Full Process Ultimate Guide How to Install Java for Minecraft Easy Step Guide for How to Install VPN for Privacy How to Install VPN Server Virtual Private Network How to Install VPN on Router A Step-by-Step Guide : Complete Guide for How to Install Anaconda How to Install Anaconda on Linux Complete Guide How to Install Anaconda on Mac: A Step-by-Step Guide How to Install Anaconda on Ubuntu: A Step-by-Step Guide How to Install Anaconda on Windows How to Install npm A Step-by-Step Guide for Beginners How to Install npm on Ubuntu Step-by-Step How to Install NVM on Ubuntu Tips, and Explanations How to Install npm on Windows Solve Common Issues How to Install NVM on Windows Troubleshooting Tips How to Install npm on Visual Studio Code How to Install Node.js on Your Machine How to Install Node.js on Linux Step-by-Step Guide How to Install Node.js on Mac Step-by-Step Guide How to Install Node Modules on Angular How to Install Node.js on Ubuntu The Latest Version How to Install Node.js on Windows Get started Full Method How to Install APK File on Your Android Device Complete Guide on How to Install APK on Android TV How to Install APK on Chromebook Step by Step Process How to Install APK on iOS A Comprehensive Guide How to Install IPA on iPhone A Complete Guide How to Install APK on Windows 10 Complete Guide How to Install Git A Step-by-Step Guide for Beginners How to Install Git Bash A Complete Step-by-Step Guide How to Install Git on Visual Studio Code How to Install GitHub Simple Step-by-Step Process How to Install Git on Mac Step-by-Step Guide How to Install Git on Linux A Step-by-Step Guide How to Install Git on Ubuntu Step-by-Step Guide How to Install Git on Windows A Simple Guide How to Install Docker How to Install Docker on Linux How to Install Docker on Mac How to Install Docker Daemon Mac How to Install Docker on Ubuntu How to Install Docker Compose on Ubuntu 20.04 How to Install Docker Compose on Windows How to Install Docker on Windows How to Install WordPress How to Install WordPress on Ubuntu How to Install WordPress Plugins How to Install WordPress on Windows 10 How to Install Kodi on Firestick How to Install Exodus on Kodi How to Install The Crew on Kodi How to Install XAMPP on Mac
0 notes
Text
蜘蛛池程序如何部署?
蜘蛛池程序是一种用于模拟大量用户访问网站的工具,通常被用于SEO优化、压力测试等场景。正确部署蜘蛛池程序可以有效提升网站的流量和性能测试效果。下面将详细介绍如何部署蜘蛛池程序。
1. 环境准备
首先,你需要确保你的服务器环境满足以下要求:
- 操作系统:Linux(推荐Ubuntu或CentOS)
- Python环境:Python 3.x
- 其他依赖库:如requests、BeautifulSoup等
你可以通过运行以下命令来安装Python和其他必要的库:
```bash
sudo apt-get update
sudo apt-get install python3-pip
pip3 install requests beautifulsoup4
```
2. 下载并解压蜘蛛池程序
从GitHub或其他代码托管平台下载蜘蛛池程序,并将其解压到你的服务器上。假设你已经下载了名为`spider_pool.zip`的文件,可以通过以下命令进行解压:
```bash
unzip spider_pool.zip -d /path/to/your/directory
```
3. 配置程序
进入解压后的目录,找到配置文件(通常是`config.py`),根据你的需求进行配置。主要配置项包括:
- 目标URL列表
- 访问频率
- 用户代理列表
- 日志记录设置
例如,配置文件中可能包含如下内容:
```python
TARGET_URLS = ['http://example.com/page1', 'http://example.com/page2']
USER_AGENTS = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36']
LOG_FILE = '/var/log/spider_pool.log'
```
4. 运行程序
完成配置后,你可以通过以下命令启动蜘蛛池程序:
```bash
python3 spider_pool.py
```
5. 监控与维护
在程序运行过程中,建议定期检查日志文件,以确保程序正常运行。同时,根据实际需求调整配置参数,以达到最佳效果。
结语
蜘蛛池程序的部署相对简单,但合理配置和监控是关键。希望本文能帮助你成功部署并利用蜘蛛池程序提升网站的流量和性能测试效果。如果你有任何问题或建议,欢迎在评论区留言讨论!
请根据上述指南进行操作,并结合实际情况调整配置。
加飞机@yuantou2048

负面删除
SEO优化
0 notes
Text
I figured out why my #bash script to get the available/total drive space of a ZFS pool mapped as a network drive to display correctly in Windows wasn't working. I forgot a "/" in the smb.conf file in the parameter pointing to the script's file path. My brain no longer function so good. I was struggling trying to figure out why it wasn't working for well over two hours. I love having severe brainfog 24/7; the other day I forgot the word "telephone", it rules. It's like a permanent concussion.
Also got XRDP working the way I want it to again. They changed around a bunch of things for remote connections in Ubuntu 24.04 re: ports for remote connections and how screen sharing/remote logins work. That was also a pain in the ass.
3 notes
·
View notes
Video
youtube
How to Install and Set Up Ubuntu 24.04 on VMware Workstation Pro 17 in Windows 11
Overview:
Setting up Ubuntu on VMware is a crucial skill for DevOps professionals who want to create isolated environments for testing, development, and automation workflows. VMware allows you to run multiple virtual machines (VMs) on a single system, enabling you to experiment with different Linux distributions without altering your primary operating system. In this hands-on guide, we’ll walk through the steps to install and configure Ubuntu on VMware, covering the key settings and best practices for optimizing performance in DevOps environments.
VMware: Getting Started
Step 1: Install VMware Workstation
To begin, you’ll need VMware Workstation or VMware Player installed on your system. Here’s how:
- Download VMware: Visit the official VMware website and download either VMware Workstation or VMware Player depending on your preference. Workstation is a paid tool with advanced features, while Player is a free option that’s perfect for basic VMs. - Install VMware: Run the installer and follow the setup wizard. Once installed, launch VMware.
Step-by-Step: Installing Ubuntu on VMware
Step 1: Download Ubuntu ISO
- Go to the [official Ubuntu website](https://ubuntu.com/download) and download the LTS (Long Term Support) version of Ubuntu, ensuring you have a stable version for long-term usage in your DevOps workflows.
Step 2: Create a New Virtual Machine in VMware
- Open VMware Workstation or VMware Player and select “Create a New Virtual Machine.” - Choose the ISO image by selecting the downloaded Ubuntu file, then click Next.
Step 3: Allocate Resources
- CPU: Assign at least 2 CPUs for smooth operation. - RAM: Allocate at least 4GB of RAM for optimal performance. You can assign more if your system allows. - Storage: Provide at least 20GB of disk space, especially if you plan to install DevOps tools.
Step 4: Installation of Ubuntu
- Start the VM, and Ubuntu’s installation wizard will appear. - Follow the prompts: choose language, keyboard settings, and select Install Ubuntu. - Choose installation type (erase disk if it’s a fresh VM) and configure time zones, user account, and password. - After installation, update your system by running: ```bash sudo apt update && sudo apt upgrade -y ```
Step 5: VMware Tools Installation
Installing VMware Tools improves VM performance, enabling better integration with the host machine.
- In VMware, go to the VM menu and select Install VMware Tools. ```bash sudo apt install open-vm-tools open-vm-tools-desktop -y sudo reboot vmware-toolbox-cmd -v ``` Verify VMware Tools Installation:
```bash vmware-toolbox-cmd -v ```
Step 6: Post-Installation Setup for DevOps
- Install Basic DevOps Tools: ```bash sudo apt install git curl vim ``` - Enable SSH Access: ```bash sudo apt install openssh-server sudo systemctl enable ssh sudo systemctl start ssh
Best Practices for Installing and Setting Up Ubuntu on VMware
1. Resource Allocation: Ensure you allocate sufficient CPU, RAM, and storage based on the workloads. For most DevOps tasks, assign at least 2 CPUs and 4GB of RAM for optimal performance. More demanding workloads may require additional resources.
2. Snapshots: Regularly take VM snapshots before major changes or installations. This allows you to revert to a stable state if something goes wrong during configuration or software testing.
3. VMware Tools Installation: Always install VMware Tools after setting up the OS. This ensures seamless mouse integration, smoother graphics, and better performance, reducing potential bugs and lag in your virtual environment.
4. Partitioning: For better performance and management, use custom partitioning if needed. This helps in allocating different parts of your virtual disk to `/`, `/home`, and `/var` partitions, improving system performance and flexibility in future updates or installations.
5. Automated Backups: Set up automated backups or export your VMs periodically. This practice is particularly important if your VMs store critical configurations, applications, or databases.
6. Networking Configuration: Ensure that your virtual machines are correctly configured to access the internet and your local network. Consider using NAT or Bridged Network options, depending on your networking needs. NAT works well for internet access, while Bridged is ideal for networked environments.
7. Security Considerations: Configure firewalls and SSH access carefully to secure your VMs from unauthorized access. Set up strong user permissions, enforce password complexity, and enable SSH keys for secure remote access.
8. Regular System Updates: Frequently update Ubuntu systems to ensure they are protected from vulnerabilities. Use the following commands to update packages: - For Ubuntu: ```bash sudo apt update && sudo apt upgrade ```
9. Monitor Resource Usage: VMware allows you to monitor CPU, memory, and storage usage. Use these tools to ensure that your VMs are not consuming excessive resources, especially in shared environments.
10. Test Environments: Use VMs as sandbox environments to test and experiment with new DevOps tools like Docker, Kubernetes, Jenkins, or Ansible before deploying them in production.
Conclusion:
By installing and setting up Ubuntu on VMware, you gain the flexibility to experiment with DevOps tools, test automation workflows, and learn Linux system administration in a safe and isolated environment. This hands-on tutorial provides you with the foundation to run and manage your Linux VMs effectively, setting you up for success in DevOps tasks ranging from development to deployment automation. Follow along in this video as we guide you step-by-step to mastering Linux installations on VMware for your DevOps journey.
how to install ubuntu 24.04,vmware player,windows 11,vmware workstation player,how to install ubuntu 24.04 lts desktop,How to Install and Set Up Ubuntu 24.04 on VMware Workstation Pro 17 in Windows 11,vmware workstation,vmware workstation 17 pro,ubuntu linux,cloudolus,cloudoluspro,linux,free,How to Post-Installation Setup For DevOps,How to Update and VMware Tools Install in Ubuntu 24.04 LTS?,Linux for DevOps,ubuntu installation,ubuntu 24.04,ubuntu,install ubuntu,
Linux Install and Setup Overview,Install and Setup VMware Workstation Pro 17,Installing Ubuntu on VMware Workstation Pro 17,Installing CentOS on VMware Workstation Pro 17,Linux Install and Setup Best Practices vmware,virtual machine,how to download and install vmware workstation pro,Hands On Guide: How to Install and Set Up Ubuntu and CentOS on VMware,centos 7,download and install vmware workstation on windows 11,the reality of using vmware,vmware tutorial,install centos 7 on vmware,installing centos 7 on vmware,ubuntu installation on vmware workstation 17,Linux Install and Setup Best Practices,cloudoluspro vmware,linux for devops,handson ubuntu,open source,linux terminal,distrotube,ubuntu is bad,linux tutorial,linux for beginners,linux commands,Linux installation,Linux beginner guide,Linux setup,how to install Linux,Linux for beginners,Linux distributions,Ubuntu installation,Fedora installation guide,Linux tips,Linux,Linux basics,DevOps basics,cloud computing,DevOps skills,Linux tutorial,Linux scripting,Linux automation,Linux shell scripting,Linux in DevOps,Ubuntu,CentOS,Red Hat Linux,DevOps tools,ClouDolus,DevOps career,Linux commands for beginners,Linux for cloud,Linux training,devops tutorial Linux,Linux commands for beginners ubuntu,cloud computing Linux for DevOps
***************************** *Follow Me* https://www.facebook.com/cloudolus/ | https://www.facebook.com/groups/cloudolus | https://www.linkedin.com/groups/14347089/ | https://www.instagram.com/cloudolus/ | https://twitter.com/cloudolus | https://www.pinterest.com/cloudolus/ | https://www.youtube.com/@cloudolus | https://www.youtube.com/@ClouDolusPro | https://discord.gg/GBMt4PDK | https://www.tumblr.com/cloudolus | https://cloudolus.blogspot.com/ | https://t.me/cloudolus | https://www.whatsapp.com/channel/0029VadSJdv9hXFAu3acAu0r | https://chat.whatsapp.com/D6I4JafCUVhGihV7wpryP2 *****************************
*🔔Subscribe & Stay Updated:* Don't forget to subscribe and hit the bell icon to receive notifications and stay updated on our latest videos, tutorials & playlists! *ClouDolus:* https://www.youtube.com/@cloudolus *ClouDolus AWS DevOps:* https://www.youtube.com/@ClouDolusPro *THANKS FOR BEING A PART OF ClouDolus! 🙌✨*
#youtube#Linux Install and Setup OverviewInstall and Setup VMware Workstation Pro 17Installing Ubuntu on VMware Workstation Pro 17Installing CentOS o#how to install ubuntu 24.04vmware playerwindows 11vmware workstation playerhow to install ubuntu 24.04 lts desktopHow to Install and Set Up#ClouDolus ClouDolusPro#ClouDolusPro
0 notes
Text
Ubuntu
not exactly related to Linux but when my SSD died. it was probably caused by me trying to compile WebKit on 2GB of RAM with a 4GB swap file.
I did on a chroot so technically but not really
I have windows 10 installed on an old HP laptop for the sole purpose of taking tests because the stupid software doesn't work in wine and has stupid VM detection and stuff. I also have windows XP on some old hard drives that I took out of old computers and didn't wipe
no, I kinda like bash
not really afraid but I find its more of a hassle than what it's worth a lot of time so I don't really bother making git repos for my stuff
my Lenovo laptop, I installed Ubuntu on it way back in 8th grade and that started my journey
nope.
probably syncthing, I'm still shocked at how well it works. I was thinking that I'd need to set up some sort of weird rsync hodge podge to get bidirectional syncing but no, syncthing does it perfectly fine
id initially say networking, especially with WiFi, due to the poor driver support, and I can't figure out how to get any networking set up properly without networkmanager. but since when NM is installed it's pretty seamless, I'd have to say sound servers for the sole problem of overhead. they're all pretty great, but cause too much overhead a lot of the time, and I have started to just use alsa on a lot of my machines.
I feel that the community is starting to become more open and friendly with newcomers. it used to be really hard because of how toxic people are but it seems to be getting a lot better. however, a lot of them are pissing on the poor. so many times I ask a question and people respond with a solution that I already said in my question doesn't work.
yeah! I wish Debian had a bit better packaging system, but a lot of the other distros are a lot more bloated, have less packages, or are a lot easier to break
why not both?
there's a lot of software I really like and I can't really think of one that I would never use again because it was bad, but if I had to choose one I'd probably say timidity because when you have fluidsynth it's kinda pointless and also limited and hard to use.
idk what "yak shaving" particularly means in this context but personally I love barebones distros so that I can set everything up the way I like it.
yes! I've compiled it on my poor Satellite laptop, which was working for over 24hrs to compile it. I've also partially compiled it on my netbook when I was trying out Gentoo but gave up halfway because it was taking too long and I had to do other stuff.
Linux ask game
1 - what was your first distro? 2 - what was your biggest linux fuckup? 3 - have you ever run rm / on real hardware? 4 - do you dual boot or have a secondary machine with windows? 5 - did you change your default shell? 6 - are you afraid of git? 7 - what was the first machine you installed linux on? 8 - do you know your way around vim keybinds? 9 - what is your favourite non-os software? 10- biggest linux pet peeve? 11- biggest annoyance with the community? 12- do you like your current distro? 13- Xenia or Tux? 14- what software are you never using again? 15- stock distro or hours of yak shaving? 16- have you compiled the kernel?
152 notes
·
View notes
Text
Debian 12 initial server setup on a VPS/Cloud server

After deploying your Debian 12 server on your cloud provider, here are some extra steps you should take to secure your Debian 12 server. Here are some VPS providers we recommend. https://youtu.be/bHAavM_019o The video above follows the steps on this page , to set up a Debian 12 server from Vultr Cloud. Get $300 Credit from Vultr Cloud
Prerequisites
- Deploy a Debian 12 server. - On Windows, download and install Git. You'll use Git Bash to log into your server and carry out these steps. - On Mac or Linux, use your terminal to follow along.
1 SSH into server
Open Git Bash on Windows. Open Terminal on Mac/ Linux. SSH into your new server using the details provided by your cloud provider. Enter the correct user and IP, then enter your password. ssh root@my-server-ip After logging in successfully, update the server and install certain useful apps (they are probably already installed). apt update && apt upgrade -y apt install vim curl wget sudo htop -y
2 Create admin user
Using the root user is not recommended, you should create a new sudo user on Debian. In the commands below, Change the username as needed. adduser yournewuser #After the above user is created, add him to the sudo group usermod -aG sudo yournewuser After creating the user and adding them to the sudoers group, test it. Open a new terminal window, log in and try to update the server. if you are requested for a password, enter your user's password. If the command runs successfully, then your admin user is set and ready. sudo apt update && sudo apt upgrade -y
3 Set up SSH Key authentication for your new user
Logging in with an SSH key is favored over using a password. Step 1: generate SSH key This step is done on your local computer (not on the server). You can change details for the folder name and ssh key name as you see fit. # Create a directory for your key mkdir -p ~/.ssh/mykeys # Generate the keys ssh-keygen -t ed25519 -f ~/.ssh/mykeys/my-ssh-key1 Note that next time if you create another key, you must give it a different name, eg my-ssh-key2. Now that you have your private and public key generated, let's add them to your server. Step 2: copy public key to your server This step is still on your local computer. Run the following. Replace all the details as needed. You will need to enter the user's password. # ssh-copy-id -i ~/path-to-public-key user@host ssh-copy-id -i ~/.ssh/mykeys/my-ssh-key1.pub yournewuser@your-server-ip If you experience any errors in this part, leave a comment below. Step 3: log in with the SSH key Test that your new admin user can log into your Debian 12 server. Replace the details as needed. ssh yournewuser@server_ip -i ~/.ssh/path-to-private-key Step 4: Disable root user login and Password Authentication The Root user should not be able to SSH into the server, and only key based authentication should be used. echo -e "PermitRootLogin nonPasswordAuthentication no" | sudo tee /etc/ssh/sshd_config.d/mycustom.conf > /dev/null && sudo systemctl restart ssh To explain the above command, we are creating our custom ssh config file (mycustom.conf) inside /etc/ssh/sshd_config.d/ . Then in it, we are adding the rules to disable password authentication and root login. And finally restarting the ssh server. Certain cloud providers also create a config file in the /etc/ssh/sshd_config.d/ directory, check if there are other files in there, confirm the content and delete or move the configs to your custom ssh config file. If you are on Vultr cloud or Hetzner or DigitalOcean run this to disable the 50-cloud-init.conf ssh config file: sudo mv /etc/ssh/sshd_config.d/50-cloud-init.conf /etc/ssh/sshd_config.d/50-cloud-init Test it by opening a new terminal, then try logging in as root and also try logging in the new user via a password. If it all fails, you are good to go.
4 Firewall setup - UFW
UFW is an easier interface for managing your Firewall rules on Debian and Ubuntu, Install UFW, activate it, enable default rules and enable various services #Install UFW sudo apt install ufw #Enable it. Type y to accept when prompted sudo ufw enable #Allow SSH HTTP and HTTPS access sudo ufw allow ssh && sudo ufw allow http && sudo ufw allow https If you want to allow a specific port, you can do: sudo ufw allow 7000 sudo ufw allow 7000/tcp #To delete the rule above sudo ufw delete allow 7000 To learn more about UFW, feel free to search online. Here's a quick UFW tutorial that might help get you to understand how to perform certain tasks.
5 Change SSH Port
Before changing the port, ensure you add your intended SSH port to the firewall. Assuming your new SSH port is 7020, allow it on the firewall: sudo ufw allow 7020/tcp To change the SSH port, we'll append the Port number to the custom ssh config file we created above in Step 4 of the SSH key authentication setup. echo "Port 7020" | sudo tee -a /etc/ssh/sshd_config.d/mycustom.conf > /dev/null && sudo systemctl restart ssh In a new terminal/Git Bash window, try to log in with the new port as follows: ssh yournewuser@your-server-ip -i ~/.ssh/mykeys/my-ssh-key1 -p 7020 #ssh user@server_ip -i ~/.ssh/path-to-private-key -p 7020 If you are able to log in, then that’s perfect. Your server's SSH port has been changed successfully.
6 Create a swap file
Feel free to edit this as much as you need to. The provided command will create a swap file of 2G. You can also change all instances of the name, debianswapfile to any other name you prefer. sudo fallocate -l 2G /debianswapfile ; sudo chmod 600 /debianswapfile ; sudo mkswap /debianswapfile && sudo swapon /debianswapfile ; sudo sed -i '$a/debianswapfile swap swap defaults 0 0' /etc/fstab
7 Change Server Hostname (Optional)
If your server will also be running a mail server, then this step is important, if not you can skip it. Change your mail server to a fully qualified domain and add the name to your etc/hosts file #Replace subdomain.example.com with your hostname sudo hostnamectl set-hostname subdomain.example.com #Edit etc/hosts with your hostname and IP. replace 192.168.1.10 with your IP echo "192.168.1.10 subdomain.example.com subdomain" | sudo tee -a /etc/hosts > /dev/null
8 Setup Automatic Updates
You can set up Unattended Upgrades #Install unattended upgrades sudo apt install unattended-upgrades apt-listchanges -y # Enable unattended upgrades sudo dpkg-reconfigure --priority=low unattended-upgrades # Edit the unattended upgrades file sudo vi /etc/apt/apt.conf.d/50unattended-upgrades In the open file, uncomment the types of updates you want to be updated , for example you can make it look like this : Unattended-Upgrade::Origins-Pattern { ......... "origin=Debian,codename=${distro_codename}-updates"; "origin=Debian,codename=${distro_codename}-proposed-updates"; "origin=Debian,codename=${distro_codename},label=Debian"; "origin=Debian,codename=${distro_codename},label=Debian-Security"; "origin=Debian,codename=${distro_codename}-security,label=Debian-Security"; .......... }; Restart and dry run unattended upgrades sudo systemctl restart unattended-upgrades.service sudo unattended-upgrades --dry-run --debug auto-update 3rd party repositories The format for Debian repo updates in the etc/apt/apt.conf.d/50unattended-upgrades file is as follows "origin=Debian,codename=${distro_codename},label=Debian"; So to update third party repos you need to figure out details for the repo as follows # See the list of all repos ls -l /var/lib/apt/lists/ # Then check details for a specific repo( eg apt.hestiacp.com_dists_bookworm_InRelease) sudo cat /var/lib/apt/lists/apt.hestiacp.com_dists_bookworm_InRelease # Just the upper part is what interests us eg : Origin: apt.hestiacp.com Label: apt repository Suite: bookworm Codename: bookworm NotAutomatic: no ButAutomaticUpgrades: no Components: main # Then replace these details in "origin=Debian,codename=${distro_codename},label=Debian"; # And add the new line in etc/apt/apt.conf.d/50unattended-upgrades "origin=apt.hestiacp.com,codename=${distro_codename},label=apt repository"; There you go. This should cover Debian 12 initial server set up on any VPS or cloud server in a production environment. Additional steps you should look into: - Install and set up Fail2ban - Install and set up crowdsec - Enable your app or website on Cloudflare - Enabling your Cloud provider's firewall, if they have one.
Bonus commands
Delete a user sudo deluser yournewuser sudo deluser --remove-home yournewuser Read the full article
0 notes
Text
Linux Zero to Hero: Mastering the Open-Source Operating System
Linux, an open-source operating system, is the backbone of countless systems, from personal computers to enterprise servers and supercomputers. It has earned its reputation as a robust, versatile, and secure platform for developers, administrators, and tech enthusiasts. In this comprehensive guide, we explore the journey from being a Linux beginner to mastering its vast ecosystem.
Why Learn Linux?
1. Open-Source Freedom
Linux provides unparalleled flexibility, allowing users to customize and modify the system according to their needs. With its open-source nature, you have access to thousands of applications and tools free of charge.
2. Industry Relevance
Major companies, including Google, Amazon, and Facebook, rely on Linux for their servers and infrastructure. Learning Linux opens doors to lucrative career opportunities in IT and software development.
3. Secure and Reliable
Linux boasts a strong security model and is known for its stability. Its resistance to malware and viruses makes it the operating system of choice for critical applications.
Getting Started with Linux
Step 1: Understanding Linux Distributions
Linux comes in various distributions, each catering to specific needs. Popular distributions include:
Ubuntu: User-friendly, ideal for beginners.
Fedora: Known for cutting-edge technology and innovation.
Debian: Stable and versatile, preferred for servers.
CentOS: Enterprise-grade, often used in businesses.
Choosing the right distribution depends on your goals, whether it’s desktop use, development, or server management.
Step 2: Setting Up Your Linux Environment
You can use Linux in several ways:
Dual Boot: Install Linux alongside Windows or macOS.
Virtual Machines: Run Linux within your current OS using tools like VirtualBox.
Live USB: Try Linux without installation by booting from a USB drive.
Mastering Linux Basics
1. The Linux File System
Linux organizes data using a hierarchical file system. Key directories include:
/root: Home directory for the root user.
/etc: Configuration files for the system.
/home: User-specific data.
/var: Variable files, such as logs and databases.
2. Essential Linux Commands
Understanding basic commands is crucial for navigating and managing the Linux system. Examples include:
ls: Lists files and directories.
cd: Changes directories.
mkdir: Creates new directories.
rm: Deletes files or directories.
chmod: Changes file permissions.
3. User and Permission Management
Linux enforces strict user permissions to enhance security. The system categorizes users into three groups:
Owner
Group
Others
Permissions are represented as read (r), write (w), and execute (x). Adjusting permissions ensures secure access to files and directories.
Advanced Linux Skills
1. Shell Scripting
Shell scripting automates repetitive tasks and enhances efficiency. Using bash scripts, users can create programs to execute commands in sequence.
Example: A Simple Bash Script
bash
Copy code
#!/bin/bash
echo "Hello, World!"
2. System Administration
System administrators use Linux for tasks like:
Managing users and groups.
Monitoring system performance.
Configuring firewalls using tools like iptables.
Scheduling tasks with cron jobs.
3. Package Management
Each Linux distribution uses a package manager to install, update, and remove software:
APT (Ubuntu/Debian): sudo apt install package_name
YUM (CentOS/Fedora): sudo yum install package_name
Zypper (openSUSE): sudo zypper install package_name
Linux for Developers
Linux provides a robust environment for coding and development. Key features include:
Integrated Development Environments (IDEs): Tools like Eclipse, IntelliJ IDEA, and Visual Studio Code are supported.
Version Control Systems: Git integration makes Linux ideal for collaborative software development.
Containerization and Virtualization: Tools like Docker and Kubernetes thrive in Linux environments.
Troubleshooting and Debugging
Learning to troubleshoot is vital for any Linux user. Common methods include:
Viewing Logs: Logs in /var/log offer insights into system errors.
Using Debugging Tools: Commands like strace and gdb help debug applications.
Network Diagnostics: Tools like ping, traceroute, and netstat diagnose connectivity issues.
Linux Certifications
Earning a Linux certification validates your skills and enhances your career prospects. Notable certifications include:
CompTIA Linux+
Red Hat Certified Engineer (RHCE)
Linux Professional Institute Certification (LPIC)
Certified Kubernetes Administrator (CKA)
These certifications demonstrate proficiency in Linux administration, security, and deployment.
Tips for Success in Linux Mastery
Practice Regularly: Familiarity with commands and tools comes through consistent practice.
Join Communities: Engage with Linux forums, such as Stack Overflow and Reddit, to learn from experienced users.
Contribute to Open-Source Projects: Hands-on involvement in projects deepens your understanding of Linux and enhances your resume.
Stay Updated: Follow Linux news and updates to stay informed about advancements and changes.
Conclusion
Mastering Linux is a transformative journey that equips individuals and organizations with the tools to thrive in a technology-driven world. By following the steps outlined in this guide, you can progress from a Linux novice to a seasoned expert, ready to tackle real-world challenges and opportunities.
0 notes
Text
Respondiendo a los Comentarios: Elección de Distribuciones de Linux y Sus Justificaciones Técnicas / Responding to Comments: Choosing Linux Distributions and Their Technical Justifications
Introducción / Introduction
Español: En el reciente artículo "¿Qué Distribución de Linux Deberías Usar Según tus Intereses?", surgieron comentarios constructivos que abordan temas clave como la seguridad en Linux, la idoneidad de Ubuntu y Mint para principiantes, y la utilización de Arch Linux en gaming. En este blog, responderé a estas inquietudes de manera más detallada y con argumentos técnicos más sólidos, explicando las razones por las que se hicieron las recomendaciones iniciales y por qué cada una de ellas tiene fundamentos bien establecidos.
English: In the recent article "Which Linux Distribution Should You Use Based on Your Interests?", constructive comments emerged that address key topics such as Linux security, the suitability of Ubuntu and Mint for beginners, and the use of Arch Linux in gaming. In this blog, I will respond to these concerns in greater detail and with stronger technical arguments, explaining the reasons behind the initial recommendations and why each one is well-founded.
Seguridad en Linux: Desmitificando el Concepto / Linux Security: Demystifying the Concept
Español: Uno de los comentarios planteó que “Linux no es inherentemente más seguro” y que, en algunos casos, podría haber más vulnerabilidades en software Linux, especialmente en servidores. Este comentario toca un punto crucial: la seguridad en cualquier sistema operativo es un tema multifacético que depende tanto del diseño del sistema como del comportamiento del usuario.
1. Diseño de Seguridad en Linux: Linux se diseñó desde sus inicios con un enfoque en la seguridad, adoptando un modelo de permisos que restringe el acceso de los usuarios a recursos críticos del sistema. A diferencia de Windows, donde históricamente los usuarios podían ejecutar aplicaciones con privilegios administrativos de manera más permisiva, en Linux, se fomenta el uso de cuentas sin privilegios para las tareas diarias. Esta segmentación minimiza el riesgo de que el software malicioso comprometa el sistema.
2. Vulnerabilidades y Actualizaciones: Aunque es cierto que los servidores Linux pueden ser objetivos frecuentes debido a su prevalencia en infraestructuras críticas, la comunidad de desarrollo de Linux es proactiva en la identificación y corrección de vulnerabilidades. La naturaleza de código abierto de Linux permite que cualquier usuario o desarrollador audite el código, lo que resulta en una respuesta más rápida a las amenazas de seguridad. Comparativamente, en entornos de software propietario, las vulnerabilidades pueden permanecer sin parchear durante más tiempo, ya que dependen exclusivamente del equipo de desarrollo interno.
3. Prácticas del Usuario: Si bien Linux facilita la implementación de buenas prácticas de seguridad, como el uso de sudo en lugar de root, es cierto que la flexibilidad del sistema permite acciones arriesgadas, como ejecutar scripts con curl piped a bash sin verificación previa. Aquí es donde la educación del usuario y la conciencia sobre la seguridad juegan un papel crucial. No obstante, esto no es una debilidad inherente de Linux, sino un reflejo de la responsabilidad que viene con la libertad de elección.
Conclusión: Linux ofrece un entorno más seguro por diseño, pero como cualquier sistema, requiere de usuarios informados para mantener su integridad. En comparación con Windows, que históricamente ha sido más vulnerable a amenazas debido a su modelo de permisos y mayor cuota de mercado en el escritorio, Linux sigue siendo una opción preferida para aquellos que valoran la seguridad.
English: One comment suggested that “Linux is not inherently more secure” and that in some cases, there might be more vulnerabilities in Linux software, especially on servers. This comment touches on a crucial point: security in any operating system is a multifaceted topic that depends on both system design and user behavior.
1. Security Design in Linux: Linux was designed from the ground up with security in mind, adopting a permission model that restricts user access to critical system resources. Unlike Windows, where users historically could run applications with administrative privileges more permissively, Linux encourages the use of non-privileged accounts for daily tasks. This segmentation minimizes the risk of malicious software compromising the system.
2. Vulnerabilities and Updates: While it’s true that Linux servers can be frequent targets due to their prevalence in critical infrastructures, the Linux development community is proactive in identifying and patching vulnerabilities. The open-source nature of Linux allows any user or developer to audit the code, leading to a faster response to security threats. In contrast, in proprietary software environments, vulnerabilities may remain unpatched for longer, as they depend solely on the internal development team.
3. User Practices: While Linux facilitates the implementation of good security practices, such as using sudo instead of root, it’s true that the system’s flexibility allows risky actions, like running scripts with curl piped to bash without prior verification. This is where user education and security awareness play a crucial role. However, this is not an inherent weakness of Linux but a reflection of the responsibility that comes with the freedom of choice.
Conclusion: Linux offers a more secure environment by design, but like any system, it requires informed users to maintain its integrity. Compared to Windows, which has historically been more vulnerable to threats due to its permission model and larger market share on the desktop, Linux remains a preferred choice for those who value security.
Ubuntu vs. Linux Mint para Principiantes: Un Análisis Comparativo / Ubuntu vs. Linux Mint for Beginners: A Comparative Analysis
Español: Algunos comentarios sugirieron que Linux Mint podría ser una mejor opción para principiantes que Ubuntu. Esta es una observación válida, ya que ambos sistemas tienen sus méritos. Sin embargo, la recomendación de Ubuntu se basa en consideraciones técnicas y prácticas específicas.
1. Ecosistema y Soporte: Ubuntu es, sin duda, una de las distribuciones de Linux más populares y bien soportadas a nivel global. Esto significa que los principiantes tienen acceso a una vasta cantidad de recursos de aprendizaje, foros, y documentación oficial y comunitaria. La enorme comunidad de usuarios y desarrolladores de Ubuntu garantiza que la mayoría de los problemas que un principiante podría enfrentar ya hayan sido documentados y resueltos, lo que facilita la curva de aprendizaje.
2. Ciclo de Actualizaciones y Estabilidad: Ubuntu sigue un ciclo de lanzamientos regulares, con versiones LTS (Long Term Support) que reciben soporte durante cinco años. Estas versiones LTS están diseñadas para ofrecer un entorno estable y fiable, lo que es crucial para los principiantes que no desean lidiar con problemas inesperados. Aunque Linux Mint se basa en Ubuntu y ofrece un entorno igualmente estable, Ubuntu tiene la ventaja de recibir actualizaciones de seguridad y software directamente desde su fuente, lo que puede ser beneficioso para quienes requieren el software más actualizado.
3. Interfaz de Usuario: Aunque Linux Mint ofrece una interfaz de usuario que imita el estilo tradicional de Windows, lo que puede resultar más cómodo para nuevos usuarios, Ubuntu ha realizado avances significativos en la optimización de su entorno de escritorio GNOME para ser intuitivo y accesible. La simplicidad de la interfaz de Ubuntu, combinada con su enfoque en la accesibilidad, hace que sea una opción atractiva para aquellos que buscan una experiencia de usuario pulida y moderna desde el principio.
Conclusión: Aunque Linux Mint es una excelente opción para principiantes, especialmente aquellos que prefieren una interfaz similar a Windows, Ubuntu se destaca por su robusto ecosistema de soporte, su estabilidad en versiones LTS y su interfaz moderna y accesible. Estas características hacen de Ubuntu una opción sólida para quienes se inician en el mundo de Linux y desean una plataforma bien soportada y documentada.
English: Some comments suggested that Linux Mint might be a better option for beginners than Ubuntu. This is a valid observation, as both systems have their merits. However, the recommendation of Ubuntu is based on specific technical and practical considerations.
1. Ecosystem and Support: Ubuntu is undoubtedly one of the most popular and well-supported Linux distributions globally. This means that beginners have access to a vast amount of learning resources, forums, and official and community documentation. Ubuntu’s large user and developer community ensures that most problems a beginner might face have already been documented and solved, making the learning curve easier.
2. Update Cycle and Stability: Ubuntu follows a regular release cycle, with LTS (Long Term Support) versions that receive support for five years. These LTS versions are designed to provide a stable and reliable environment, which is crucial for beginners who do not want to deal with unexpected issues. While Linux Mint is based on Ubuntu and offers an equally stable environment, Ubuntu has the advantage of receiving security and software updates directly from its source, which can be beneficial for those who require the most up-to-date software.
3. User Interface: While Linux Mint offers a user interface that mimics the traditional Windows style, which may be more comfortable for new users, Ubuntu has made significant strides in optimizing its GNOME desktop environment to be intuitive and accessible. The simplicity of Ubuntu’s interface, combined with its focus on accessibility, makes it an attractive option for those looking for a polished and modern user experience right from the start.
Conclusion: While Linux Mint is an excellent option for beginners, especially those who prefer a Windows-like interface, Ubuntu stands out for its robust support ecosystem, its stability in LTS versions, and its modern and accessible interface. These features make Ubuntu a solid choice for those new to Linux who want a well-supported and documented platform.
Arch Linux para Gaming: ¿Es Realmente una Buena Opción? / Arch Linux for Gaming: Is It Really a Good Option?
Español: Un comentario afirmó que Arch Linux no es la mejor opción para gaming a menos que sepas lo que estás haciendo. Este es un punto muy importante y refleja la realidad de Arch Linux como una distribución de Linux que exige un conocimiento avanzado por parte del usuario.
1. Filosofía de Arch Linux: Arch Linux sigue la filosofía de "mantenerlo simple", lo que en este contexto significa dar al usuario control absoluto sobre su entorno. Esto incluye la instalación y configuración del sistema desde cero, lo que puede ser desafiante para usuarios no experimentados. Sin embargo, para gamers avanzados, esta flexibilidad permite optimizar el sistema para obtener el máximo rendimiento de hardware, lo cual es crucial en un entorno de gaming competitivo.
2. Actualización y Acceso a las Últimas Tecnologías: Arch Linux es una distribución rolling release, lo que significa que siempre está a la vanguardia en cuanto a la última tecnología, controladores y software. Esto puede ser una ventaja significativa para los gamers que desean acceso inmediato a los últimos avances en controladores gráficos o software de gaming. Sin embargo, esta misma característica puede introducir inestabilidades si las actualizaciones no se manejan correctamente, lo que refuerza la necesidad de experiencia técnica.
3. Comparación con Otras Distribuciones: En comparación, distribuciones como Pop!_OS están diseñadas específicamente para usuarios interesados en gaming, ofreciendo un entorno preconfigurado con soporte robusto para GPU y menos complicaciones en la instalación y configuración inicial. Arch Linux, por otro lado, ofrece la ventaja de una personalización extrema y acceso a lo último en tecnología, pero a costa de una curva de aprendizaje mucho más pronunciada.
Conclusión: Arch Linux es una excelente opción para gamers que buscan personalizar y optimizar su entorno al máximo, pero no es la elección más sencilla ni la más directa. Su naturaleza rolling release y la necesidad de conocimientos técnicos avanzados hacen que sea ideal para usuarios experimentados. Para la mayoría de los usuarios, distribuciones como Pop!_OS o Ubuntu con configuraciones adecuadas pueden ofrecer una experiencia de gaming más accesible y estable.
English: A comment stated that Arch Linux is not the best choice for gaming unless you know what you’re doing. This is a very important point and reflects the reality of Arch Linux as a Linux distribution that demands advanced knowledge from the user.
1. Arch Linux Philosophy: Arch Linux follows the philosophy of "keeping it simple," which in this context means giving the user absolute control over their environment. This includes installing and configuring the system from scratch, which can be challenging for inexperienced users. However, for advanced gamers, this flexibility allows optimizing the system to get the maximum hardware performance, which is crucial in a competitive gaming environment.
2. Updates and Access to the Latest Technologies: Arch Linux is a rolling release distribution, meaning it is always at the cutting edge in terms of the latest technology, drivers, and software. This can be a significant advantage for gamers who want immediate access to the latest developments in graphics drivers or gaming software. However, this same feature can introduce instabilities if updates are not managed correctly, reinforcing the need for technical expertise.
3. Comparison with Other Distributions: In comparison, distributions like Pop!_OS are specifically designed for users interested in gaming, offering a preconfigured environment with robust GPU support and fewer complications in initial setup and configuration. Arch Linux, on the other hand, offers the advantage of extreme customization and access to the latest technology, but at the cost of a much steeper learning curve.
Conclusion: Arch Linux is an excellent choice for gamers looking to customize and optimize their environment to the fullest, but it’s not the easiest or most straightforward choice. Its rolling release nature and the need for advanced technical knowledge make it ideal for experienced users. For most users, distributions like Pop!_OS or Ubuntu with appropriate configurations may offer a more accessible and stable gaming experience.
Conclusión Final / Final Conclusion
Español: Agradezco nuevamente los comentarios y la oportunidad de profundizar en las recomendaciones iniciales. La elección de una distribución de Linux debe basarse en una combinación de factores técnicos, prácticos y personales. Ubuntu se recomienda por su soporte y estabilidad, Mint por su accesibilidad, y Arch Linux por su capacidad de personalización extrema. Sin embargo, cada usuario debe considerar sus propias necesidades y nivel de experiencia al elegir su distribución ideal.
English: I appreciate the comments and the opportunity to delve deeper into the initial recommendations. The choice of a Linux distribution should be based on a combination of technical, practical, and personal factors. Ubuntu is recommended for its support and stability, Mint for its accessibility, and Arch Linux for its extreme customization capability. However, each user should consider their own needs and experience level when choosing their ideal distribution.
#Linux#DistribucionesLinux#Ubuntu#LinuxMint#ArchLinux#GamingLinux#SeguridadLinux#DesarrolloSoftware#PersonalizaciónLinux#DebateLinux#SistemaOperativo#LinuxSeguridad#LinuxPrincipiantes#LinuxAvanzados
0 notes
Text
post documenting my process for downloading scrivener 3.1.5.1 with wine on ubuntu 23.10 for my own future reference
download the win64 executable at https://www.literatureandlatte.com/scrivener/download
enable 32-bit architecture through terminal:
sudo dpkg --add-architecture i386
install wine stuff through terminal:
sudo apt-get install winetricks wine64 wine32:i386 winbind -y
install scrivener through the terminal:
wine ~/Downloads/Scrivener-Installer.exe
for some reason, winbind didn't install all of its prerequisites properly, so reinstall it:
sudo apt-get remove winbind && sudo apt-get install winbind
change windows version to windows 10 via winecfg
use winetricks to install stuff:
winetricks --force corefonts win10 dotnet48
if it fails, retry until it works
for some reason, this didn't let me activate my scrivener license, so run another command:
winetricks --force dotnet462
doing this said it failed, but scrivener let me activate after this regardless, so i don't know.
make a file called "scrivener" and open it in kate:
touch scrivener && kate scrivener
edit it to be a bash script that runs scrivener when called in terminal:
#!/bin/bash
cd "/home/vhou/.wine/drive_c/Program Files/Scrivener3" && wine Scrivener.exe
move the file to /usr/bin/ so it can be called anywhere:
sudo mv -v scrivener /usr/bin/
run scrivener and it should work normally:
scrivener
1 note
·
View note
Text
Docker
Readme
What is Docker and why is it popular?
Take note: The following instructions are run in a ubuntu-xenial virtual machine setup using Vagrant. To do the same, you can also install docker in any Vagrant virtual machine, or install docker on your host OS (Windows, Linux or Mac OS)
Let’s first pull a Docker image and run a container:
vagrant@ubuntu-xenial:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES vagrant@ubuntu-xenial:~$ docker run -d -ti ubuntu:16.04 Unable to find image 'ubuntu:16.04' locally 16.04: Pulling from library/ubuntu 34667c7e4631: Pull complete d18d76a881a4: Pull complete 119c7358fbfc: Pull complete 2aaf13f3eff0: Pull complete Digest: sha256:58d0da8bc2f434983c6ca4713b08be00ff5586eb5cdff47bcde4b2e88fd40f88 Status: Downloaded newer image for ubuntu:16.04 e1fc0d4bbb5d3513b8f7666c91932812da7640346f6e05b7cfc3130ddbbb8278 vagrant@ubuntu-xenial:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e1fc0d4bbb5d ubuntu:16.04 "/bin/bash" About a minute ago Up About a minute keen_blackwell vagrant@ubuntu-xenial:~$
Note that docker command will pull the Ubuntu docker container image from the Internet and run it. I let you look at the meaning of the flags using the command docker run --help, the main idea is that it keeps the container up and running.
To execute a command on the Docker container, use docker exec:
vagrant@ubuntu-xenial:~$ docker exec -i e1fc0d4bbb5d hostname e1fc0d4bbb5d vagrant@ubuntu-xenial:~$ hostname ubuntu-xenial vagrant@ubuntu-xenial:~$
If you want to connect to your Docker container and use Bash, you need to use docker exec -ti:
vagrant@ubuntu-xenial:~$ docker exec -ti e1fc0d4bbb5d /bin/bash root@e1fc0d4bbb5d:/# echo "I am in $(hostname) Docker container" I am in e1fc0d4bbb5d Docker container root@e1fc0d4bbb5d:/# exit exit vagrant@ubuntu-xenial:~$
If you want to stop a container, use docker stop:
vagrant@ubuntu-xenial:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e1fc0d4bbb5d ubuntu:16.04 "/bin/bash" 5 minutes ago Up 5 minutes keen_blackwell vagrant@ubuntu-xenial:~$ docker stop e1fc0d4bbb5d e1fc0d4bbb5d vagrant@ubuntu-xenial:~$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES vagrant@ubuntu-xenial:~$
0 notes